Three ways to improve the EF Core performance in your .NET Core app

ORM (object-relational mapping) frameworks really simplify the developer’s life for all database-related tasks.
However, as it usually happens, such simplification comes with a price. In most cases, the price is flexibility and performance.
In this article, I’m going to describe the three most straightforward approaches to increase the performance of Entity Framework Core (EF Core) operations in your .NET Core applications.
1. Don’t be lazy. Be eager
We start with the most obvious advice, which actually can give you the biggest performance boost in some cases when EF Core is not used correctly.
So, imagine the following very common situation:
- You have a master-detail relationship between two entities. Let it be a classic Order — Customer example where each Order entity references one Customer.
- You need to retrieve the information about all orders for the specified period (e.g., from the beginning of this year) and also show the name of the customer for each order.
EF Core 2.1 introduced a thing called “lazy-loading” (or rather“re-introduced” since this feature was available in the good-old Entity Framework 6.x), so now you can implement the described task with the following piece of code:
var thisYearFirstDay = new DateTime(DateTime.Now.Year, 1, 1);
var thisYearOrders = context.Orders
.Where(o => o.OrderDate > thisYearFirstDay);foreach (var order in thisYearOrders)
{
Console.WriteLine($"{order.Id} {order.OrderDate} {order.Customer.CompanyName}");
}
Pretty easy, right?
WRONG! It’s actually pretty lazy :) and you will get a huge performance blow with this code.
Why? Simply because EF Core will convert your code to 1+N queries to the database where N — is the number of records in the thisYearOrders result set.
If you add a logger to your DbContext and look at logging messages, you will see one query like this:
SELECT [o].[OrderID], [o].[CustomerID], . . .
FROM [Orders] AS [o]
WHERE [o].[OrderDate] > @__thisYearFirstDay_0and then N queries like this:
SELECT [e].[CustomerID], [e].[Address], . . .
FROM [Customers] AS [e]
WHERE [e].[CustomerID] = @__get_Item_0Obviously, such a number of queries will take a lot of time, especially with a poor connection or a large database.
To resolve this problem we need to use the so-called “eager loading” and add the `Include` call to our request:
var thisYearOrders = context.Orders
.Include(o => o.Customer)
.Where(o => o.OrderDate > thisYearFirstDay);Now, if we look at our log, we will see only one query instead of 1+N:
SELECT [o].[OrderID], [o].[CustomerID], . . . /* all other columns from Orders and Customers */
FROM [Orders] AS [o]
LEFT JOIN [Customers] AS [o.Customer] ON [o].[CustomerID] = [o.Customer].[CustomerID]
WHERE [o].[OrderDate] > @__thisYearFirstDay_0As you might suppose, the “eager” approach will be executed much faster than a “lazy” one.
In real-world applications, the advantage can be valued in hundreds or even thousands of percent!
2. Don’t be too much eager. Take only what you’ll use
The problem with the “eager” approach from our first example is that it can be too “eager” in most cases.
Look, we actually need only three fields (two from the Orders table and one from Customers), but instead, we take the whole set of columns from both tables.
The solution is simple: take only those columns that you need with a Select call:
var thisYearFirstDay = new DateTime(DateTime.Now.Year, 1, 1);
var thisYearOrders = context.Orders
.Where(o => o.OrderDate > thisYearFirstDay)
.Select(o => new { o.Id, o.OrderDate, o.Customer.CompanyName })foreach (var rec in thisYearOrders)
{
Console.WriteLine($"{rec.Id} {rec.OrderDate} {rec.CompanyName}");
}
The resulting SQL statement will look like this:
SELECT [o].[OrderID] AS [Id], [o].[OrderDate], [o.Customer].[CompanyName]
FROM [Orders] AS [o]
LEFT JOIN [Customers] AS [o.Customer] ON [o].[CustomerID] = [o.Customer].[CustomerID]
WHERE [o].[OrderDate] > @__thisYearFirstDay_0It will definitely have better performance since there will be less data to transfer from the DB server to the client (your .NET app, in this case).
There are two things in the code above which should be noticed.
First of all, we don’t need a Include call anymore since Entity Framework “understands” from the Select call that we need a field (Customer.CompanyName) from another table and adds the necessary JOIN clause to the result SQL automatically.
Secondly, as you can see, we create a list of dynamic objects (objects that don’t belong to any particular class) with that new {o.Id, ...} command.
To emphasize this fact, we have replaced the name of the variable in our foreach loop from order to rec (from “record”) — because it’s not an “Order” anymore. The dynamic objects we get in the result contain only three properties: Id, OrderDate, and CompanyName (that’s why we access `CompanyName` directly now instead of `order.Customer.CompanyName` in previous cases).
3. Use AsNoTracking(). But wisely
When you run a query over some entities in your DbContext, the returned objects are automatically tracked by the context to allow you to modify them (if necessary) and then save the changes with context.SaveChanges() operations.
However, if it’s a read-only query and the returned data is not supposed to be modified, it is not necessary to have the context perform some extra work required to establish that tracking. The AsNoTracking method tells Entity Framework to stop that additional work so it can improve the performance of your application.
So, in theory, a query with AsNoTracking should perform better than without. The question is: how much better? Let’s figure it out.
I’ve created a small testing application using the BenchmarkDotNet library. Here are two functions that were examined:
public void GetAll_WithTracking()
{
var allRecords = _dbContext.OrderDetails;
var list = allRecords.ToList();
}public void GetAll_NoTracking()
{
var allRecords = _dbContext.OrderDetails.AsNoTracking();
var list = allRecords.ToList();
}
As we expected “NoTracking” way performs better. In general, it appears to be 1.5 times faster than “WithTracking”:
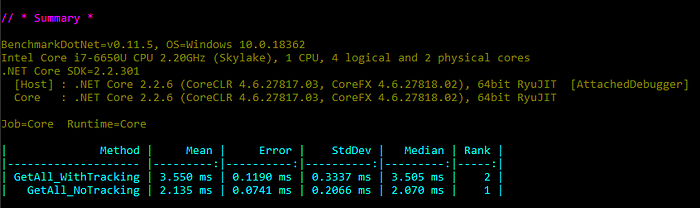
Strange things start when we try to add AsNoTracking to the query over two tables (with JOIN):
public void GetWithInclude_Tracking()
{
var allRecords = _dbContext.OrderDetails
.Include(od => od.Product); var list = allRecords.ToList();
}public void GetWithInclude_NoTracking()
{
var allRecords = _dbContext.OrderDetails
.AsNoTracking()
.Include(od => od.Product); var list = allRecords.ToList();
}
The results are confusing:
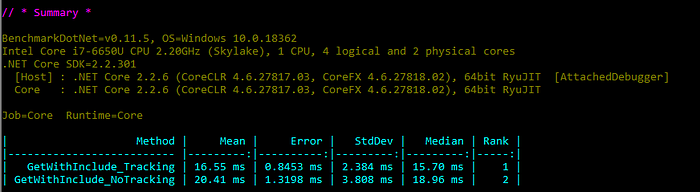
The query with tracking performs slightly better than without!
There is an issue on GitHub about such strange (at first glance) behavior.
However, this behavior can be quite logical if we try to imagine how Entity Framework is implemented inside. The query that joins two tables needs the records from both of them to make the matching, which obviously occurs faster if these records are already tracked by the context and so are stored in memory.
This is only my guess, though. Let me know if you have any other thoughts on that.
Wrapping up
I hope my suggestions about the performance improvements listed in this article will help you to write more efficient code.
I only want to give you one more general advice: Use the source :)
In terms of working with EF Core, it means: taking a look at the SQL statements generated by your code (you can see them in the Output panel in your VS while debugging).
It allows you to understand what happens “under the hood” and, in some cases, might help you to significantly increase the performance of your app.
Thank you for reading. Have a nice day!

