Database Normalization: A Data Architect’s Superpower

In the sprawling metropolis of data management, Data Architects emerge as the unsung heroes, shaping the skyline with structured, efficient, and reliable data repositories. These professionals are the masterminds who plan and create the blueprints for data storage, ensuring that information is not only accessible but also meaningful and consistent. At the heart of their toolkit lies a powerful instrument — database normalization.
A “database” is akin to a vast digital library, housing an organization’s critical data. It’s an intricate system where information, from customer details to product inventories, is stored, retrieved, and managed. But just like a library with misplaced and duplicated books can frustrate readers, a database without structure can lead to inefficiencies and inaccuracies.
Enter “data normalization”, the process that refines this digital library. It meticulously organizes, streamlines, and eliminates redundancies within databases. Just as a librarian might sort books by genre, author, and title, normalization categorizes and structures data to optimize its utility and accuracy. For Data Architects, mastering this process is not just a skill — it’s a superpower, elevating their designs from functional repositories to optimized, harmonious systems.
As we delve further into this topic, we will uncover the magic behind database normalization and why it’s considered a Data Architect’s ultimate weapon in creating impeccable data structures.
“Why, you might wonder, is data normalization such a pivotal piece in the grand puzzle of database management?”
The Villains: Issues in Unnormalized Databases
1. Data Redundancy: Exploring the perils of repetitive data
Data redundancy occurs when the same data is duplicated in multiple places within a database without a clear reason.
Example: Consider a simplistic database of students and the courses they are enrolled in:

Issue: Notice that for every course Alice enrolls in, her name is repeated. Likewise, Mr. Smith’s name is repeated for every student taking Math. This repetition results in:
- Increased chances of data inconsistency: If Alice’s name needs to be corrected, it has to be corrected in multiple places.
- Wasted storage: More space is needed to store repeated information.
2. Update Anomalies: How inconsistent data can erode the reliability of a database
Update anomalies arise when data is changed in one place but not in another, leading to inconsistencies.
Example: Continuing with the previous example, Suppose Alice changes her name to “Alicia”. If the update isn’t made in all records, you’ll end up with some records referring to her as “Alice” and others as “Alicia”, causing confusion.
Issue:
- Loss of Data Integrity: Different parts of the database give different information about the same entity.
- Increased Maintenance Effort: To ensure consistency, every instance of a piece of data must be found and updated, which is cumbersome and error prone.
3. Wasted Storage and Performance Issues: The inefficiencies and slowdowns that can plague an unnormalized system
Wasted storage is the unnecessary space taken up by redundant data. Performance issues arise when the database has to sift through or update unnecessary or repetitive data, causing delays.
Example: Continuing with the above example, Given the repetitive nature of the data, if there were thousands of students and courses, the database would be bloated with repeated entries. Every query would have to sift through more data than necessary, and every update would have to contend with these redundancies.
Issue:
- Decreased Query Efficiency: Operations like searches, updates, and deletions take longer as they have to process more data than necessary.
- Maintenance Challenges: Backing up or migrating the database becomes more challenging and time-consuming due to its inflated size.
“In conclusion, while these “villains” might seem harmless in small datasets, as a database grows, these issues can compound, leading to significant inefficiencies, increased costs, and reduced data reliability. Normalization offers methods to combat these villains, ensuring that databases remain efficient, consistent, and reliable.”
Steps of Normalization:
Database normalization is a process used to organize a database into tables and columns to reduce redundancy and improve data integrity. The main idea is to isolate data so that additions, deletions, and modifications of a field can be made in just one table, and then propagated through the rest of the database using defined relationships.
1. First Normal Form (1NF):
- Each table has a primary key: a unique identifier for each record.
- Data is stored in a tabular form with rows and columns.
- Each column contains atomic (indivisible) values.
Example: Consider a table of customers, where a customer can have multiple phone numbers.
Before 1NF:

After 1NF:
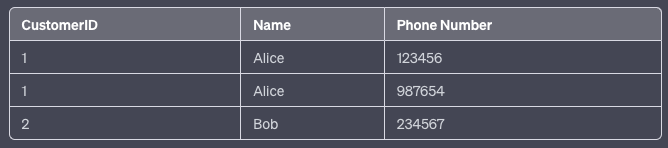
2. Second Normal Form (2NF):
- The table is in 1NF.
- All non-key columns are fully dependent on the primary key.
Example: Consider a table of customers and their orders.
Before 2NF:
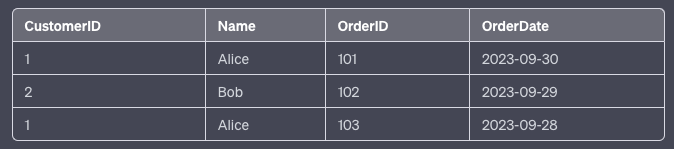
After 2NF:
- Customer Table

- Order Table

3. Third Normal Form (3NF):
- The table is in 2NF.
- There are no transitive dependencies, meaning non-key columns are not dependent on other non-key columns.
Example: Consider a table containing information about customers, their orders, and the city and country where they live.
Before 3NF:

After 3NF:
- Customer and Location Table

- City Table

“Yes, I understand that the distinction between 2NF and 3NF can sometimes be subtle. Let’s elaborate on the differences.”
Example to Clarify the Difference — 2NF vs 3NF:
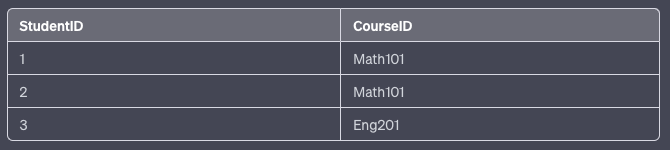
Consider an example where a Student is enrolled in multiple Courses, and each Course is taught by an Instructor.
Before Normalization:

- The primary key here is a composite of StudentID and CourseID.
- Instructor and InstructorEmail depend on CourseID, not the complete primary key, leading to partial dependency, which violates 2NF.
- Also, InstructorEmail depends on the Instructor, not the primary key, leading to a transitive dependency, which violates 3NF.
2NF Correction:
We separate the table into two tables to remove partial dependency.
- StudentCourse:
- CourseInstructor:

Now, every non-key attribute is fully dependent on the composite primary key.
3NF Correction:
We further separate the tables to remove transitive dependency.
- CourseInstructor:

- InstructorDetail:

Now, every non-key attribute is only dependent on the primary key, and there are no transitive dependencies.
So, in summary:
- 2NF addresses the issue of partial dependencies by ensuring all non-key attributes are fully dependent on the full set of primary key attributes.
- 3NF takes it a step further by ensuring there are no transitive dependencies; non-key attributes must be dependent only on the primary key, not on other non-key attributes.
“There are further advanced stages of normalization beyond the 3NF! Though many organizations have their databases normalized up till 3NF, it is beneficial to know what lies beyond the 3NF normalization.”
Advanced Normalizations: Beyond 3NF
4. Boyce-Codd Normal Form (BCNF):
BCNF is an extension of 3NF. A table is in BCNF if it is in 3NF and if X is a super key for every non-trivial functional dependency X → Y. In other words, for each functional dependency, the left side of the dependency must be a super key.
Example: Consider a university database where students can register for multiple courses, and courses can have multiple instructors. The primary key is a composite of StudentID and CourseID.
Before BCNF:

In this table, there is a dependency between CourseID and Instructor. But Instructor is not dependent on the composite key (StudentID, CourseID). It’s dependent only on CourseID.
After BCNF:
- Student-Course Table:
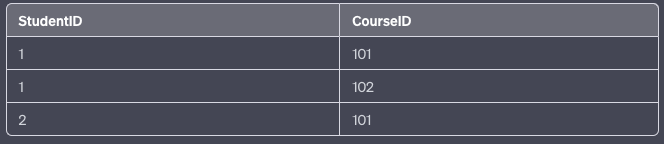
- Course-Instructor Table:

5. Fourth Normal Form (4NF):
A table is in 4NF if it is in BCNF and it does not have multi-valued dependencies, meaning an attribute is independent of another attribute in the same table.
Example: Consider a database tracking club members and the clubs’ activities. A member can be part of multiple clubs, and a club can have multiple activities.
Before 4NF:

There are multi-valued dependencies, as activities are dependent on the club, not on the member.
After 4NF:
- Member-Club Table:

- Club-Activity Table:

6. Fifth Normal Form (5NF):
A table is in 5NF if it is in 4NF, and every join dependency in the table is a consequence of the candidate keys of the table. It deals with cases where information can be reconstructed from smaller pieces of information that can be maintained with less redundancy.
Example: Consider a university scenario where students can register for multiple courses, and each course can have multiple instructors.
Initial Table:
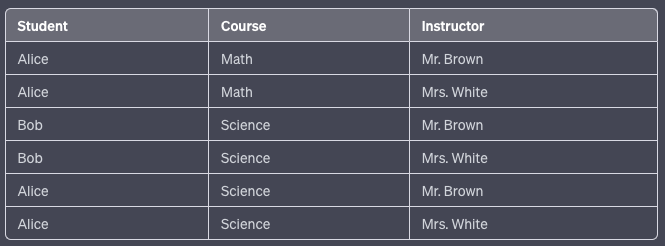
In this example, there are combinations of students, courses, and instructors. However, suppose the university operates in a way where an instructor is fixed for a course regardless of the student (e.g., both Alice and Bob have Mr. Brown and Mrs. White for Science).
This table is then subject to join dependency because the combination of (Student, Course) and (Course, Instructor) can fully determine the table.
To be in 5NF, you would break it down:
Table 1 — StudentCourse:
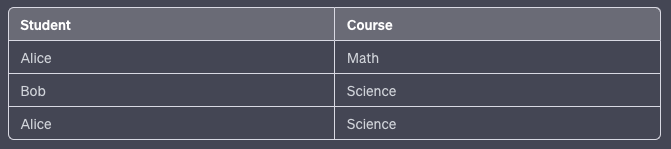
Table 2 — CourseInstructor:
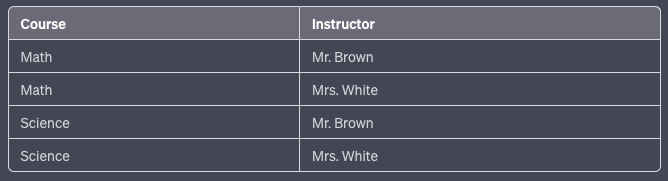
Now, there’s no redundancy in terms of who teaches what course, and the student registrations for courses are separate. The information can be reconstructed from these smaller pieces without redundancy.
So, by breaking the initial table into two separate tables, you’ve ensured that the information is in 5NF: there’s no redundancy, and any join dependency is based on the candidate keys.
These normal forms (beyond 3NF) are used less frequently in practice but are essential for understanding complex relational database designs and ensuring minimal redundancy and maximum consistency in the database.
“Now that we have understood the basics of existing forms of database normalizations, how do we get started with it?”

Tips & Strategies:
- Understand the Objectives: Before diving into normalization, be clear about its objectives. The main goal is to minimize redundancy and prevent undesirable anomalies, such as update anomalies.
- Start with ER Diagrams: Entity-Relationship (ER) diagrams can be a good starting point. They visually represent entities and relationships, making it easier to spot redundancies and other potential problems.
- Use Real-world Scenarios: When designing a database schema, think of real-world scenarios that the database needs to handle. This will help you identify functional dependencies.
- Decompose Tables when Necessary: If a table does not meet the requirements of a specific normal form, decompose it into two or more tables.
- Ensure Lossless Join: After decomposing tables, ensure that you can still retrieve original data by joining these tables.
- Preserve Functional Dependencies: As you decompose tables, ensure that all functional dependencies are preserved.
- Regularly Review: Over time, as business requirements change, the database schema might also need adjustments. Periodically review your database design for possible denormalization or further normalization.
- Beware of Over-normalization: While normalization is beneficial, overdoing it can lead to performance issues and unnecessary complexity. It’s okay to de-normalize in situations where performance is more critical than avoiding redundancy.
- Stay Updated with Real-world Feedback: Regularly talk to developers, DBAs, and end-users. Their feedback can provide insights into potential issues and areas for optimization.
- Backup Before Major Changes: Before making significant changes to a normalized database, ensure you have backups. This provides a safety net in case things don’t go as planned.
- Consider Read vs. Write Workloads: Sometimes, a more normalized structure can benefit write operations at the expense of read operations. Conversely, a denormalized structure might optimize read operations at the cost of writes. Strike a balance based on your application’s needs.
- Implement Integrity Constraints: Constraints like primary keys, foreign keys, and check constraints ensure data integrity during the normalization process.
- Document the Design: Always document your database design decisions. This not only helps other team members understand your rationale but also aids in future reviews and updates.
Closing Notes:
In summary, while database normalization is a powerful tool for database design, it requires a keen understanding of data relationships, attention to detail, and a careful balance between eliminating redundancy and maintaining performance.
Disclaimer
The data and the content furnished here are thoroughly researched by the author from multiple sources before publishing and the author certifies the accuracy of the article. The opinions presented in this article belong to the writer, which may not represent the policy or stance of any mentioned organization, company or individual. In this article you have the option to navigate to websites that’re not, within the authors control. Please note that we do not have any authority, over the nature, content, and accessibility of those sites. The presence of any hyperlinks does not necessarily indicate a recommendation or endorsement of the opinions presented on those sites.
About the Author
Murali is a Senior Engineering Manager with over 14 years of experience in Engineering, Data Science, and Product Development, and over 5+ years leading cross-functional teams worldwide. Murali’s educational background includes — MS in Computational Data Analytics from Georgia Institute of Technology, MS in Information Technology & Systems design from Southern New Hampshire University, and a BS in Electronics & Communication Engineering from SASTRA University.

