ReDoS Attacks: How Regex Can Bring Down Your System and How to Avoid Them
About Evil Regexes, How to Check, and How to Avoid Them.
“Some people, when confronted with a problem, think ‘I know, I’ll use regular expressions.’ Now they have two problems.”
- Jamie Zawinski

ReDoS
ReDoS stands for Regular Expression Denial of Service. It’s a type of attack that exploits regular expressions, patterns used to match or manipulate strings. Most -if not all- programming languages support regular expression (regex) capabilities. If you code, you’re most likely familiar with regex.
ReDoS attacks are caused by regular expressions that take a long time to evaluate and consume high CPU on the server. When I say a long time, the run time can be exponential related to the input length, it can literally be a long time to evaluate. Just in case you’re not aware yet, StackExchange (you know, StackOverflow) was down in 2016 because of the evil regex, even though it’s not an exponential run time (the run time was O(n²)), it was enough, see their postmortem here. Cloudflare also went down in 2019 because of a poorly written regex pattern, they got 100% CPU usage worldwide, dropping up to 82% of traffic, see their blog here.
Regex and Backtracking
So, what’s the problem with regex? We need to go to the beginning. There are many ways for a regex engine can be implemented. For example, .NET languages and JavaScript employ a “backtracking” engine, or “regex-directed” engine.
Backtracking in regex is a process which the regex engine attempts to match a pattern against a given input, it’s the mechanism which the regex engine explores different possibilities to find a match. For example, if you have a pattern like a* and the input is aaa, the regex engine may match the aa, then backtrack to try matching a, and even an empty string. If a branch of pattern fails to match at some point in the input string, the regex engine backtracks to a previous point where it had other options and tries a different path. It does this until all possibilities travelled or a match is found.
Backtracking in regex can be computationally expensive, especially with complex patterns and long input strings. It can lead to performance issues in certain cases, it can cause an issue known as “catastrophic backtracking”. It usually occurs when we’re checking a long input against a complex pattern, also if towards the end of the input string causes it to not match. We’ll see examples later.
The time complexity of this backtracking can yield exponential run time O(2ⁿ). Just for an example of a bad regex pattern, a string like this random.email.address@gmail.com with the length of only 31 characters will have 2³¹ possibilities, it’s more than 2 billion. With a long enough string of text, you will need to wait until the heat death of the universe before it finishes matching 😲. So be careful when you copy some regex patterns from somewhere.
Examples
To see how bad the backtracking in regex can be (or any exponential time complexity algorithm in general), let’s see this example in C# (using the snippet code by Microsoft here).
var sw = new Stopwatch();
for (int i = 10; i <= 25; i++)
{
var r = new Regex($@"^(\w\d|\d\w){{{i}}}$");
string input = new('1', (i * 2) + 1);
sw.Restart();
r.IsMatch(input);
sw.Stop();
Console.WriteLine($"{i}: {sw.Elapsed.TotalMilliseconds:N}ms");
}Here’s the result from my computer.
10: 0.79ms
11: 0.52ms
12: 1.35ms
13: 2.38ms
14: 4.75ms
15: 8.80ms
16: 9.50ms
17: 16.63ms
18: 39.56ms
19: 72.23ms
20: 144.57ms
21: 372.80ms
22: 1,267.67ms
23: 2,961.73ms
24: 6,391.17ms
25: 13,355.15ms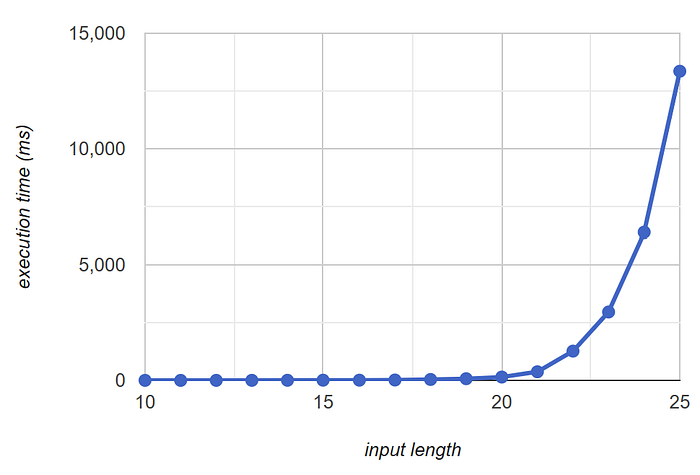
I also did an experiment by testing this code below in debug mode on my computer to show you how much the CPU is consumed by just only 5 sessions:
var pattern = @"^[0-9A-Z]([-.\w]*[0-9A-Z])*$";
var input = "AAAAAAAAAAaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa!@contoso.com"; // nearly matched, the character "!" make it to not match.
var isMatched = Regex.IsMatch(input, pattern2, RegexOptions.IgnoreCase);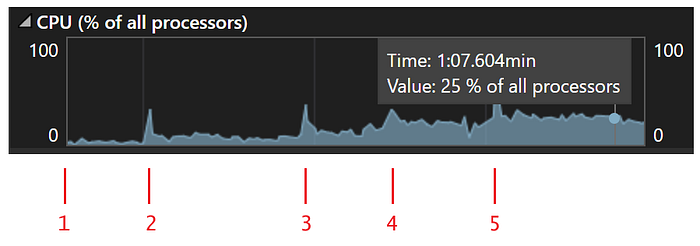
It consumed one-fourth of the CPU, imagine if it’s in a web server and has a lot of sessions.
But doing the same thing in Go, we don’t see the same issue happening. Let’s see the “equivalent” example below.
package main
import (
"fmt"
"regexp"
"strings"
"time"
)
func main() {
for i := 10; i <= 25; i++ {
re := regexp.MustCompile(fmt.Sprintf(`^(\w\d|\d\w){%d}$`, i))
input := strings.Repeat("1", (i*2)+1)
startTime := time.Now()
re.MatchString(input)
elapsed := time.Since(startTime)
fmt.Printf("%d: %.6fms\n", i, float64(elapsed.Milliseconds()))
}
}The result for all iteration is effectively 0 ms.
This is because Go regex uses RE2 algorithm, and RE2 doesn’t do backtracking. RE2 employs finite automata from the graph theory, it guarantees linear performance against input length and the regex pattern length O(mn). It’s also the same reason why Go regex has less features than Perl or .NET regex.
Some programming languages don’t do backtracking for their regex engine, but some do. The behavior can also be different among programming languages. You always want to check their documentation, or you can go here to try different flavors of regex.
How to guess the evil regex patterns?
There are some ways to quick guess that a regex pattern may lead to an excessive backtracking. Usually by checking if there are any nested constructs that have + or * like this one ^([a-zA-Z0-9]+\s?)*$.
But to make sure it’s really safe, you’ll need to test it, you can test it here on regex101 (it also has a useful debugger), you can set the timeout of the regex matching there. There’s also a useful online tool to check regex pattern here https://devina.io/redos-checker that you can try, let’s see the example below.
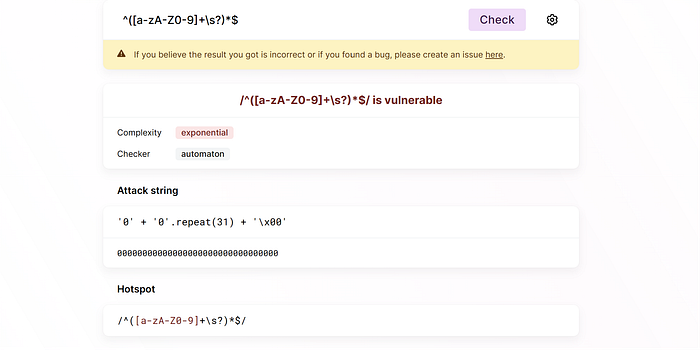
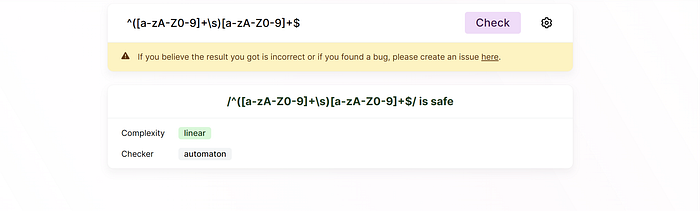
How to avoid?
There are ways to avoid the regex catastrophic backtracking in some programming languages. In C# for example, we can pass a timeout when matching a pattern and it will throw RegexMatchTimeoutException when the timeout occurs (you’ll also need to handle the exception), like this:
try
{
var input = "some random text again and again and again.";
var pattern = "^([a-zA-Z0-9]+\\s?)*$";
var matchTimeout = TimeSpan.FromMilliseconds(1500);
var isMatched = Regex.IsMatch(input, pattern, RegexOptions.IgnoreCase, matchTimeout);
Console.WriteLine(isMatched);
}
catch (RegexMatchTimeoutException rex)
{
// do something with the exception
}Starting from .NET 7, we can pass a regex option NonBacktracking so that the algorithm to match the pattern will not use backtracking, the run time will be linear. You can read it here on Microsoft blog, it has a dedicated long article for it. There are some caveats by using NonBacktracking option as mentioned in the blog though, one of them is -as for now- it only supports providing the last match value in a capture group, as do most other regex implementations.
var input = "some random text again and again and again.";
var pattern = "^([a-zA-Z0-9]+\\s?)*$";
var matchTimeout = TimeSpan.FromMilliseconds(1500);
var isMatched = Regex.IsMatch(input, pattern, RegexOptions.IgnoreCase | RegexOptions.NonBacktracking, matchTimeout);
Console.WriteLine(isMatched);If we go back to our previous code sample and use this non backtracking option, we’ll see something like this:
var sw = new Stopwatch();
for (int i = 10; i <= 25; i++)
{
var r = new Regex($@"^(\w\d|\d\w){{{i}}}$", RegexOptions.NonBacktracking);
string input = new('1', (i * 2) + 1);
sw.Restart();
r.IsMatch(input);
sw.Stop();
Console.WriteLine($"{i}: {sw.Elapsed.TotalMilliseconds:N}ms");
}The result
10: 0.14ms
11: 0.14ms
12: 0.12ms
13: 0.10ms
14: 0.11ms
15: 0.11ms
16: 0.12ms
17: 0.12ms
18: 0.12ms
19: 0.13ms
20: 0.14ms
21: 0.15ms
22: 0.16ms
23: 0.16ms
24: 0.16ms
25: 0.17msIn the end, before you’re doing any of those above, if the programming language’s regex that you’re working on does backtracking, you may need to check the regex pattern and find an alternative pattern with the same result but with more performant run time. You may also need to validate the length of the input before matching it, or you may need to consider other simpler string checking options other than regex. Be careful with regex as it can cause problems we saw earlier in this article.

