Usage of Gunicorn for deploying python web applications
Tutorial on how to use and configure Gunicorn
Introduction
First of all, what is a Gunicorn and what do we need it for? According to the definition from the official site:
Gunicorn ‘Green Unicorn’ is a Python WSGI HTTP Server for UNIX.
So what is a WSGI server and what makes it different from a web server? WSGI stands for Web Server Gateway Interface and it is needed for Python web applications, because traditional web servers like Apache don’t have the ability to run them.
In other words, WSGI server is an application server. The main difference between a web server and application server is that a web server is meant to serve static pages like HTML and CSS, while an Application Server is responsible for working with data by executing server-side code. Usually for serving static content we use servers like Nginx, but it can also be any other web server or CDN. In that case, Nginx is used as a reverse proxy server, which is also responsible for:
- load balancing — it is responsible for determining on which application server incoming HTTP request will be sent (ensuring load balancing over existing application servers)
- acceleration — it also cashes some common responses with static content
The typical set up for a python web app is on the image below.
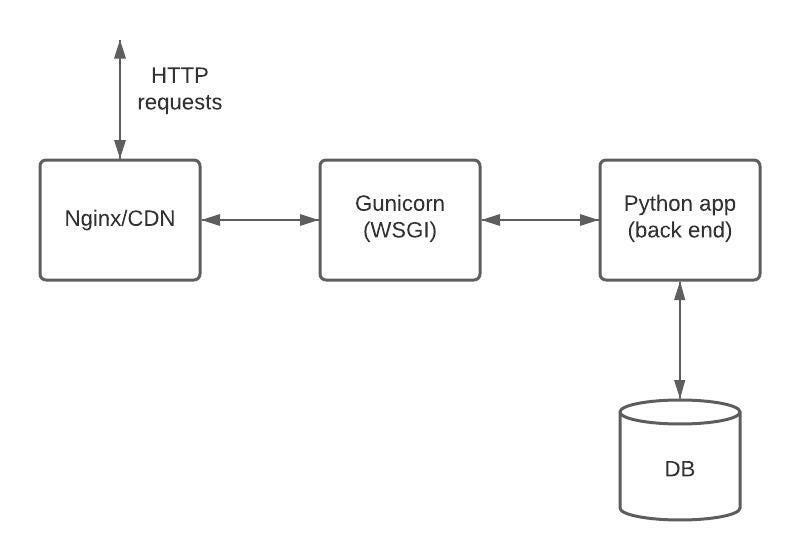
Gunicorn as well as other WSGI servers work with all popular web frameworks like flask or django. But contrary to other servers like waitress it uses pre-fork worker model. This means that there is a central master process that manages a set of worker processes. The master never knows anything about individual clients. All requests and responses are handled completely by worker processes.
Workers in their turn can be Sync or Async (there are also some other types of available workers, but they are not very popular, so we’ll focus only on these 2).
Sync workers are workers that handle a single request at a time. They do not support persistent connections - each connection is closed after the response has been sent.
Async workers available are based on Greenlets (Greenlets are an implementation of cooperative multi-threading for Python) In general, an application should be able to make use of these worker classes with no changes.
Regarding numbers of workers, Gunicorn should only need 4–12 worker processes to handle hundreds or thousands of requests per second.
Gunicorn relies on the operating system to provide all of the load balancing when handling requests. Generally, it is recommended to have:
2 * Number of cores + 1
workers. It is based on the assumption that for a given core, one worker will be reading or writing from the socket while the other worker is processing a request. Although this can be tuned further for the particular application.
Setting up a simple app and serving with Gunicorn
Let’s set up a small Flask app and serve it with the Gunicorn. For that we’ll need a “Hello world” Flask app with 1 endpoint:
Now, let’s create an entry point for serving our application:
Running this will start Gunicorn with 4 workers, 2 threads by each worker and serving our application on port 5000.
Create a Dockerfile:
Now build and run our image:
docker build -t hello .
docker run -p 5000:5000 helloAnd accessed with http request:
$ curl localhost:5000
Hello world!Summary
In this tutorial, we have looked through the Gunicorn and how it works. We have seen that adding Gunicorn is fast and easy.

